Work Term #2: Distributed cross-collection joins
![]()
Anything I say here is my own words, and does not represent Bloomberg LP. All images inside this post can either be found online or are public information.
Click here to learn more about my overall experience at Bloomberg.
Fixed Income Core - Search Team
In Winter 2018, I joined the Fixed Income Search Team. My team was responsible for powering all Fixed Income Search functionality on Bloomberg Terminals (including SRCH and 70+ other functions including DDIS and LEAG). My work was heavily focused on their search infrastructure, and extending the capabilities of Apache Solr’s (open-source search platform) cross-collection join.

Introducing high-performance join capabilities for sharded collections and SolrCloud clusters to Solr was my primary project. By allowing for joins across sharded collections, the Lucene indices could be scaled horizontally across many nodes allowing for larger collections and faster performance. Joins across SolrCloud clusters allows different teams to perform joins across their datasets without the need of duplicate data - which was an issue for our team. As teams shift towards Bloomberg’s new infrastructure for “Solr as a service”, teams could very quickly join across data-sets by simply providing the ZooKeeper host address for the other SolrCloud cluster. This has impact not only for my team, but for many other teams across all of Bloomberg.
// ZooKeeper host allows for retrieval of clusterstate for cross-cloud joins
fq={!join from=inner_id to=outer_id zkHost=192.12.3.17 fromIndex=cB}zzz:vvv
// Allows for nested joins as well
fq={!join from=inner_id to=outer_id zkHost=192.12.3.17 fromFq="...." fromIndex=cB}zzz:vvv
The general stages of the join are:
- The join is invoked as a
PostFilter, meaning that its caching behavior indicates it runs after the otherfqqueries. This is the best practice for heavier queries. - The containerization process begins in
JoinQParserPlugin, which then will create a newCrossCloudJoinPostFilterinstead of the traditional single-sharded cross-core joins. - After instantiating the query object, it extends the
ExtendedQueryBase, meaning terms will be collected inDelegatingCollectorand intersected with the “from collection” documents. - Fetching the ZooKeeper clusterstate information, making it possible to map/reduce to all the shards and retrieve the values in a distributed fashion.
- For rapid retrieval of fields, Lucene uninverting data-structures (namely
NumericDocValuesandBinaryDocValues) are used allowing forO(n)retrieval (n= document count) - To trigger the uninverting data-structures, a custom request handler is invoked allowing for nested joins and marshalling the results back in
javabinserialization format. - Results are unmarshalled and aggregated in either a hashset or roaring bitmap (cache friendly compressed bitset) and intersected while traversing using
LeafReaderContext. - Collect documents that intersect in the
DelegatingCollectorif they are found in the bitmap or hashset - these are the final join result documents.
Performance is critical for Bloomberg Terminal users, and as a result the join was very heavily profiled and optimized. In short, migrating from streaming expression’s intersect to the newer join code reduces query times on average by 87.3%! I created an automated benchmarking system allowing for chart visualizations and regressions, appropriate JVM warming up, collection cache resetting along with deploying SolrCloud clusters and ZooKeeper ensembles across Bloomberg’s New York and New Jersey datacenters.
The most significant speed-up came from leveraging uninverting data-structures from Lucene, which allow for rapid field-lookups. By creating a custom request handler endpoint on Solr, this allows for rapid retrieval of fields that can be sent back in proprietary binary format over the network. I also researched heavily different data-structures and compression techniques. This included leveraging LZ4, Burrows-Wheeler Transform and Huffman Coding for strings, in addition to a custom join for my team leveraging compressed (roaring) bitmaps. At the end, I prepared the patch to be pushed upstream, which included documentation and unit tests.
For my team specifically, the compressed roaring bitmaps allowed for much superior performance due to CPU spatial cache locality, improvement of runs and reducing over the network latency via compression. Following the original implementation of the roaring bitmaps, the bitmaps is partioning into three types of sub-bitmaps depending on the density of runs.
The size of the partions are set to align with CPU cache lines, below is an example (albiet using the simpler binary-type roaring model):
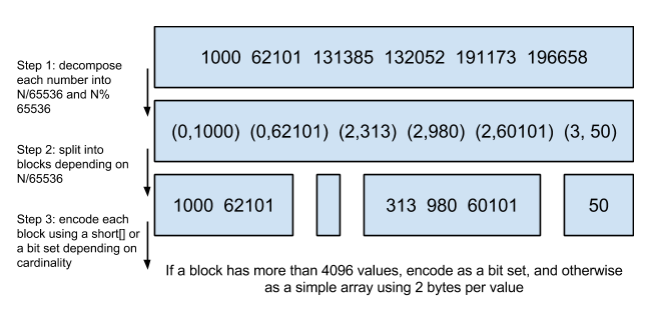
Lastly, I also worked on designing a middleware service integrating Solr with Bloomberg’s service oriented architecture. Applications of this includes augmenting search results with real-time pricing, leveraging Apache Spark services for time-series bond screening and more! This project involved creating custom handlers in Java for Solr, in addition to creating schemas and a C++ service that can interact with other Bloomberg services.
As always, I would like to thank my mentor and team lead (in addition to the open-source community!) for providing guidance on my work. I had a blast working on Solr, and found the project very challenging but also rewarding.